ℹ️ 注意: 此页面不再进行维护。要获取更更新的脚本和扩展列表,您可以使用Web UI内置的选项卡(
Extensions->Available),
或者您也可以在Github上访问扩展索引,网址为https://github.com/AUTOMATIC1111/stable-diffusion-webui-extensions
通用信息
扩展是用户脚本的一种更方便的形式。
扩展都存在于webui的extensions文件夹中的各自文件夹中。您可以使用git来安装扩展,如下所示:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients extensions/aesthetic-gradients
这将把https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients中的扩展安装到extensions/aesthetic-gradients目录中。
或者,您也可以直接复制粘贴一个目录到extensions中。
有关开发扩展的信息,请参阅开发扩展。
安全性
由于扩展允许用户安装和运行任意代码,这可能被恶意使用,并且在使用允许远程用户连接到服务器的选项(--share或--listen)运行时默认禁用 - 您仍然可以使用UI,但尝试安装任何内容都会导致错误。如果您想使用这些选项并仍然能够安装扩展,请使用--enable-insecure-extension-access命令行标志。
扩展
使用平铺VAE的多扩散
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
多扩散
- txt2img全景生成,如多扩散中所述。
- 它可以与ControlNet合作,生成带有控制的宽图像。
全景示例:(链接在2023年6月无法使用) 之前:点击查看原始图像 之后:点击查看原始图像
{kind=link}
{kind=link}
ControlNet Canny 输出:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/raw/docs/imgs/yourname.jpeg?raw=true
平铺VAE
vae_optimize.py 脚本将图像分割成平铺,分别对每个平铺进行编码,然后合并结果。这个过程允许VAE使用有限的VRAM(对于8K图像约为10GB)生成大图像。
使用这个脚本可能允许去除 --lowvram 或 --medvram 参数,从而提高图像生成时间。
VRAM 估算器
https://github.com/space-nuko/a1111-stable-diffusion-webui-vram-estimator
运行txt2img、img2img、highres-fix,逐渐增加尺寸和批处理大小,直到内存不足,并将数据输出到图表。

Dump U-Net
https://github.com/hnmr293/stable-diffusion-webui-dumpunet
查看不同层,观察U-Net特征图。通过为unet的每个块提供不同的提示来生成图像:https://note.com/kohya_ss/n/n93b7c01b0547

posex
https://github.com/hnmr293/posex
Pose2Image的估计图像生成器。该扩展允许在3D空间中移动openpose图像。

LLuL
https://github.com/hnmr293/sd-webui-llul
局部潜在增强器。针对特定区域进行选择性增强细节。
CFG-Schedule-for-Automatic1111-SD
https://github.com/guzuligo/CFG-Schedule-for-Automatic1111-SD
这两个脚本允许在生成步骤中动态控制CFG。通过正确的设置,即使在img2img中进行低降噪,也可以帮助获取高CFG的细节而不损坏生成的图像。
请参阅它们的wiki以了解如何使用。
a1111-sd-webui-locon
https://github.com/KohakuBlueleaf/a1111-sd-webui-locon 用于在webui中加载LoCon网络的扩展。
ebsynth_utility
https://github.com/s9roll7/ebsynth_utility
用于使用img2img和ebsynth创建视频的扩展。使用ebsynth输出编辑后的视频。与ControlNet扩展一起使用。

LoRA块权重
LoRA是一个强大的工具,但有时很难使用,并且可能会影响您不想影响的区域。这个脚本允许您逐块设置权重。使用这个脚本,您可能能够获得您想要的图像。
与XY图一起使用,可以检查层次结构的每个级别的影响。

包含的预设值:
``` NOT:0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ALL:1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 INS:1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0 IND:1,0,0,0,1,1,1,1,0,0,0,0,0,0,0,0,0,0 INALL:1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0 MIDD:1,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0 OUTD:1,0,0,0,0,0,0,0,0,
可组合的LoRA
https://github.com/opparco/stable-diffusion-webui-composable-lora
允许使用AND关键字(可组合扩散)将LoRA限制在子提示中。与Latent Couple扩展配对使用时非常有用。
Clip Interrogator
https://github.com/pharmapsychotic/clip-interrogator-ext
将pharmapsychotic的Clip Interrogator移植为一个扩展。具有各种剪辑模型和询问设置。

Latent-Couple
https://github.com/opparco/stable-diffusion-webui-two-shot
内置Composable Diffusion的扩展,允许您确定反映子提示的潜在空间的区域。

OpenPose Editor
https://github.com/fkunn1326/openpose-editor
可以添加多个姿势角色,从图像中检测姿势,保存为PNG,并发送到controlnet扩展。

SuperMerger
https://github.com/hako-mikan/sd-webui-supermerger
合并并运行,无需保存到驱动器。按顺序合并XY生成;提取并合并LoRA;将LoRA绑定到ckpt;合并块权重等。

Prompt Translator
https://github.com/butaixianran/Stable-Diffusion-Webui-Prompt-Translator
一个集成的翻译器,使用Deepl或Baidu将提示翻译成英语。

Video Loopback
https://github.com/fishslot/video_loopback_for_webui
https://user-images.githubusercontent.com/122792358/218375476-a4116c74-5a9a-41e2-970a-c3cc09f796ae.mp4
Mine Diffusion
https://github.com/fropych/mine-diffusion
该扩展可以将图像转换为方块,并创建方案图以便使用Litematica模组轻松导入到Minecraft中。
示例:(点击展开)
anti-burn
https://github.com/klimaleksus/stable-diffusion-webui-anti-burn
通过跳过最后几个步骤并对它们之前的一些图像进行平均,来平滑生成的图像。

嵌入合并
https://github.com/klimaleksus/stable-diffusion-webui-embedding-merge
在运行时从字符串文字中合并文本反转嵌入。

gif2gif
这个脚本的目的是接受一个动态gif作为输入,像img2img一样处理帧,并将它们重新组合成一个动态gif。旨在提供一个有趣、快速的gif到gif的工作流程,支持新的模型和方法,如Controlnet和InstructPix2Pix。只需放入一个gif并开始。引用了来自prompts_from_file的代码。
示例:(点击展开)
cafe-aesthetic
https://github.com/p1atdev/stable-diffusion-webui-cafe-aesthetic
预训练模型,用于确定美学/非美学,具有5种不同的风格识别模式和Waifu确认。还有一个批处理选项卡。

Catppuccin主题
https://github.com/catppuccin/stable-diffusion-webui
Catppuccin是一个社区驱动的柔和主题,旨在成为低对比度和高对比度主题之间的中间地带。添加了一组符合catppucin指南的主题。

动态阈值化
动态阈值化添加了可定制的动态阈值化功能,允许使用高CFG比例值而不会出现烧毁或“流行艺术”效果。
自定义扩散
https://github.com/guaneec/custom-diffusion-webui
自定义扩散是一种使用TI进行微调的方法,而不是调整整个模型。与TI具有相似的速度和内存要求,并且可能在较少的步骤中获得更好的结果。
融合
https://github.com/ljleb/prompt-fusion-extension
添加了类似于prompt-travel和shift-attention的插值(参见exts),但是在采样步骤期间/内部进行。始终开启+与现有的prompt编辑语法一起使用。各种插值模式。请参阅他们的维基了解更多信息。
示例:(点击展开)
像素化
https://github.com/AUTOMATIC1111/stable-diffusion-webui-pixelization
使用预训练模型,在“extras”选项卡中将图像生成像素艺术。

Instruct-pix2pix
https://github.com/Klace/stable-diffusion-webui-instruct-pix2pix
添加了一个选项卡,可以使用instruct-pix2pix模型进行img2img编辑。作者已经将此功能添加到了webui中,因此不需要使用此选项卡。
System Info
https://github.com/vladmandic/sd-extension-system-info
在Automatic WebUI中创建一个顶级的System Info选项卡,其中包含以下信息:
注意: - 如果选项卡可见,则状态和内存信息每秒自动更新 (选项卡不可见时不进行更新) - 所有其他信息在WebUI加载时更新一次, 如果需要,可以强制刷新
Steps Animation
https://github.com/vladmandic/sd-extension-steps-animation
扩展程序用于从去噪的中间步骤创建动画序列 在txt2img和img2img选项卡中注册了一个脚本
创建动画对整体性能的影响很小,因为它不需要单独运行,只需增加保存每个中间步骤为图像的开销,以及几秒钟的时间来创建电影文件。
支持颜色和运动插值,以从任意数量的中间步骤实现所需持续时间的动画。 由于优化的编解码器设置,生成的电影文件通常非常小(平均约为1MB)。
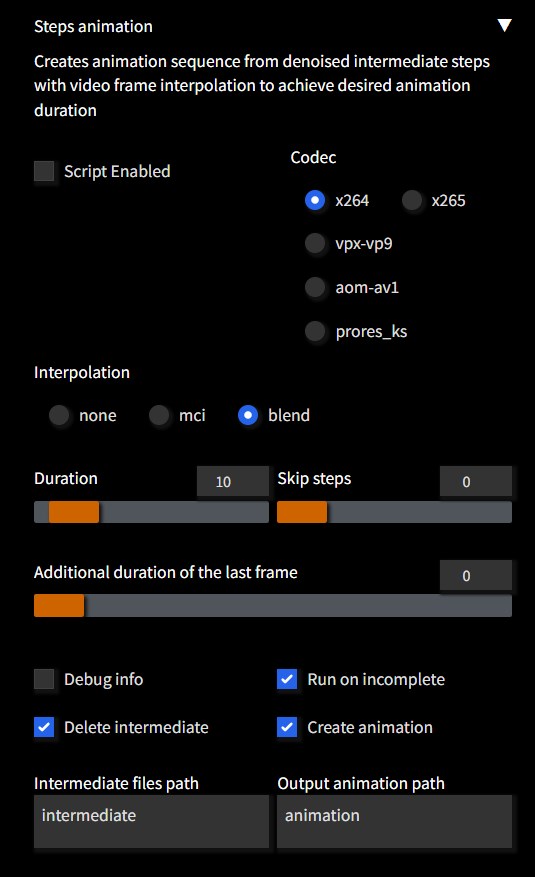
示例
美学评分器
https://github.com/vladmandic/sd-extension-aesthetic-scorer
使用现有的CLiP模型和额外的小型预训练模型来计算图像的感知美学分数。
通过设置->美学评分器启用或禁用。
这是一个“隐形”的扩展,它在任何图像保存之前在后台运行,并将score作为PNG信息部分和/或EXIF注释字段附加上去。
注意事项
- 通过设置 → 美学评分器进行配置
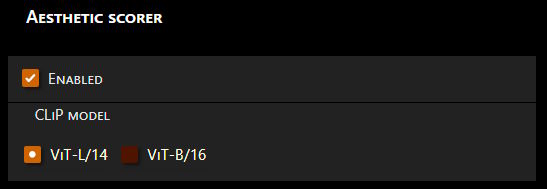
- 扩展遵循现有的将VAE和CLiP移至RAM设置
- 模型将在首次使用时自动下载(很小)
- 分数值为
0..10 - 支持
CLiP-ViT-L/14和CLiP-ViT-B/16 - 跨平台!
Discord Rich Presence
https://github.com/kabachuha/discord-rpc-for-automatic1111-webui
提供与Discord RPC的连接,可以在用户个人资料中显示一个漂亮的表格。
Promptgen
https://github.com/AUTOMATIC1111/stable-diffusion-webui-promptgen
使用transformers模型生成提示。

haku-img
https://github.com/KohakuBlueleaf/a1111-sd-webui-haku-img
图像工具扩展。可以进行混合、叠加、色调和颜色调整、模糊和素描效果以及基本像素化。

Merge Block Weighted
https://github.com/bbc-mc/sdweb-merge-block-weighted-gui
合并模型,每个25个U-Net块(输入、中间、输出)都有单独的权重。

稳定的Horde Worker
https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker
作为稳定的Horde工作器的非官方桥接,作为稳定的Diffusion WebUI的扩展。
特点
该扩展仍在开发中,尚未准备好用于生产环境。
- 从稳定的Horde获取作业,生成图像并提交生成
- 可配置的作业之间的间隔
- 随时启用和禁用扩展
- 检测当前模型并实时获取相应的作业
- 在稳定的Diffusion WebUI中显示生成图像
- 将带有png信息文本的生成图像保存到本地
安装
- 在稳定的Diffusion WebUI安装的根目录中运行以下命令:
bash
git clone https://github.com/sdwebui-w-horde/sd-webui-stable-horde-worker.git extensions/stable-horde-worker
- 启动稳定的Diffusion WebUI,您将看到
Stable Horde Worker选项卡页面。

- 在Stable Horde上注册一个账户并获取你的
API密钥,如果你还没有的话。
注意:默认的匿名密钥00000000对于一个工作者来说是无效的,你需要注册一个账户并获取你自己的密钥。
- 在这里设置你的
API密钥。 - 在这里设置一个合适的
工作者名称。 - 确保勾选了
启用。 - 点击
应用设置按钮。
Stable Horde
Stable Horde客户端
https://github.com/natanjunges/stable-diffusion-webui-stable-horde
使用其他用户的计算机生成图片。你应该能够使用匿名的0000000000API密钥从稳定的部落接收图片,但建议你获取自己的密钥-https://stablehorde.net/register
注意:检索图片可能需要2分钟或更长时间,特别是如果你没有赞助。
多个超网络
https://github.com/antis0007/sd-webui-multiple-hypernetworks
这个扩展允许同时使用多个超网络。

Hypernetwork-Monkeypatch-Extension
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension
这个扩展提供了额外的训练功能,用于超网络训练,并支持多个超网络。

Ultimate SD Upscaler
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111
这个扩展提供了更高级的SD放大选项,使用更高的去噪比(0.3-0.5),减少了原始放大的伪影。
Model Converter
https://github.com/Akegarasu/sd-webui-model-converter
这个模型转换扩展支持转换fp16/bf16无ema/仅ema的安全张量。
Kohya-ss Additional Networks
https://github.com/kohya-ss/sd-webui-additional-networks
允许Web UI使用由其脚本训练的网络(LoRA)生成图像。编辑safetensors提示和附加元数据,并使用2.X LoRA。

将图像编号添加到网格中
https://github.com/AlUlkesh/sd_grid_add_image_number
将图像的编号添加到网格中的图片中。
quick-css
https://github.com/Gerschel/sd-web-ui-quickcss
用于快速选择和应用custom.css文件的扩展,用于自定义UI中元素的外观和位置。


Prompt Generator
https://github.com/imrayya/stable-diffusion-webui-Prompt_Generator
在Web UI中添加一个选项卡,允许用户从一个小的基本提示生成一个提示。基于FredZhang7/distilgpt2-stable-diffusion-v2。

model-keyword
https://github.com/mix1009/model-keyword
自动将匹配的关键词插入到提示中。更新扩展以获取最新的模型+关键词映射。

sd-model-preview
https://github.com/Vetchems/sd-model-preview
允许您创建一个与您的模型同名的txt文件和jpg/png文件,并在以后的参考中轻松显示这些信息。

Enhanced-img2img
https://github.com/OedoSoldier/enhanced-img2img
支持批处理和更好的修复的扩展。有关更多详细信息,请参阅readme。

openOutpaint扩展
https://github.com/zero01101/openOutpaint-webUI-extension
一个带有完整openOutpaint用户界面的选项卡。使用--api标志运行。

保存中间图像
https://github.com/AlUlkesh/sd_save_intermediate_images
实现保存中间图像的功能,具有更高级的特性。



Riffusion
https://github.com/enlyth/sd-webui-riffusion
使用Riffusion模型在gradio中生成音乐。要复制原始插值技术,请将prompt travel extension的输出帧输入到riffusion选项卡中。


DH Patch
https://github.com/d8ahazard/sd_auto_fix
由D8ahazard创建的随机修补程序。自动加载v2、2.1模型的配置YAML文件;修补latent-diffusion以修复2.1模型上的注意力问题(没有no-half的黑盒),以及其他我能想到的问题。
预设工具
https://github.com/Gerschel/sd_web_ui_preset_utils
用于UI的预设工具。支持一些自定义脚本的预设。

配置预设
https://github.com/Zyin055/Config-Presets
添加了一个可配置的下拉菜单,允许您在txt2img和img2img选项卡中更改UI预设设置。

扩散防御者
https://github.com/WildBanjos/DiffusionDefender
用于半私密和公共实例的提示黑名单、查找和替换工具。
不安全内容检查器
https://github.com/AUTOMATIC1111/stable-diffusion-webui-nsfw-censor
将不安全的图片替换为黑色。
无限网格生成器
https://github.com/mcmonkeyprojects/sd-infinity-grid-generator-script
使用您选择的参数构建一个yaml文件,并生成无限维度的网格。内置能力可以向字段添加描述文本。有关使用详细信息,请参阅自述文件。

嵌入式检查器
https://github.com/tkalayci71/embedding-inspector
检查任何标记(单词)或文本反转嵌入,并找出哪些嵌入是相似的。您可以在几秒钟内混合、修改或创建嵌入。更多有趣的选项已经发布,详见这里。

提示库
https://github.com/dr413677671/PromptGallery-stable-diffusion-webui
构建一个填满您角色提示的yaml文件,点击生成,通过它们的单词属性和修饰符快速预览。

DAAM
https://github.com/toriato/stable-diffusion-webui-daam
DAAM代表Diffusion Attentive Attribution Maps。输入注意力文本(必须是包含在提示中的字符串)并运行。将生成一个包含每个注意力热图的重叠图像,以及原始图像。

可视化交叉注意力
https://github.com/benkyoujouzu/stable-diffusion-webui-visualize-cross-attention-extension
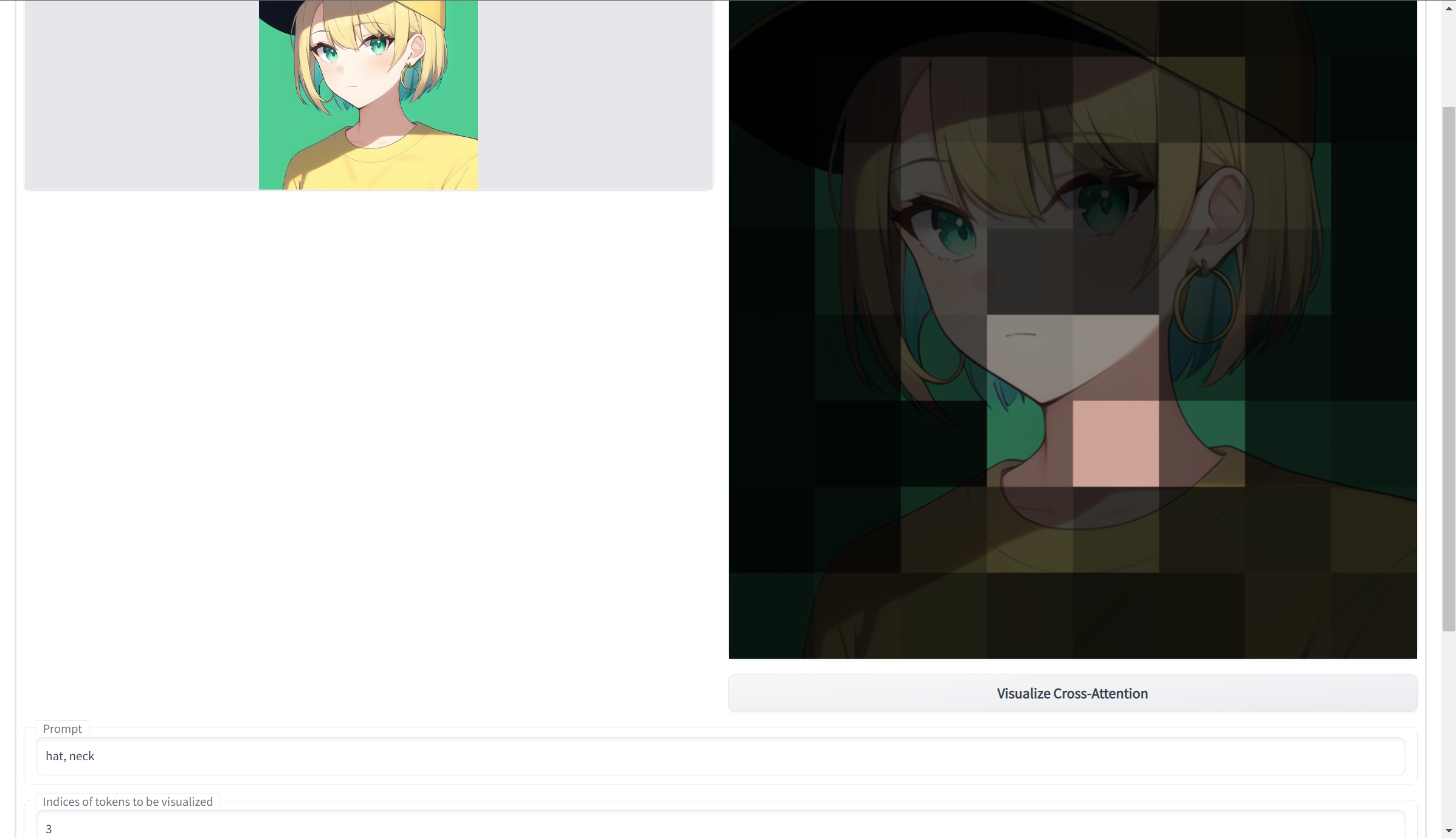
根据输入的提示生成输入图像的突出显示部分。与tokenizer扩展一起使用。有关更多信息,请参阅自述文件。
ABG_extension
https://github.com/KutsuyaYuki/ABG_extension
自动去除背景。使用针对动漫图像进行微调的onnx模型。在GPU上运行。
 |
 |
 |
 |
|---|---|---|---|
 |
 |
 |
 |
depthmap2mask
https://github.com/Extraltodeus/depthmap2mask
根据MiDaS进行的深度估计为img2img创建遮罩。



multi-subject-render
https://github.com/Extraltodeus/multi-subject-render
这是一个深度感知的扩展,可以帮助在单个图像上创建多个复杂的主题。它生成一个背景,然后是多个前景主题,在深度分析后剪切它们的背景,将它们粘贴到背景上,最后进行图像转换以获得清晰的效果。

Depth Maps
https://github.com/thygate/stable-diffusion-webui-depthmap-script
从生成的图像中创建深度图。结果可以在3D或全息设备上查看,如VR头盔或lookingglass显示器,也可以在渲染或游戏引擎中使用平面位移修饰器,甚至可以进行3D打印。

Merge Board
https://github.com/bbc-mc/sdweb-merge-board
多车道合并支持(最多10个)。将您的合并组合保存和加载为简单文本的配方。

也可以参考: https://github.com/Maurdekye/model-kitchen
gelbooru-prompt
https://github.com/antis0007/sd-webui-gelbooru-prompt
使用图像的哈希值获取标签。
booru2prompt
https://github.com/Malisius/booru2prompt
这个SD扩展允许你将各种图像booru的帖子转化为稳定的扩散提示。它通过从API中获取标签列表来实现。你可以自己复制粘贴要使用的帖子链接,或者使用内置的搜索功能,在不离开SD的情况下完成所有操作。

也可以参考: https://github.com/stysmmaker/stable-diffusion-webui-booru-prompt
WD 1.4 Tagger
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
使用训练好的模型文件,生成WD 1.4标签。模型链接 - https://mega.nz/file/ptA2jSSB#G4INKHQG2x2pGAVQBn-yd_U5dMgevGF8YYM9CR_R1SY

DreamArtist
https://github.com/7eu7d7/DreamArtist-sd-webui-extension
通过对比性提示调整,实现可控的一次性文本到图像生成。

Auto TLS-HTTPS
https://github.com/papuSpartan/stable-diffusion-webui-auto-tls-https
允许您轻松地,甚至完全自动地开始使用HTTPS。
Randomize
~~https://github.com/stysmmaker/stable-diffusion-webui-randomize~~ fork: https://github.com/innightwolfsleep/stable-diffusion-webui-randomize
允许在txt2img生成过程中使用随机参数。无论选择了哪个脚本,此脚本都会被处理,这意味着此脚本也可以与其他脚本一起使用,例如AUTOMATIC1111/stable-diffusion-webui-wildcards。
conditioning-highres-fix
https://github.com/klimaleksus/stable-diffusion-webui-conditioning-highres-fix
这是一个扩展,用于在运行时重写修复掩膜强度相对于去噪强度。这对于修复模型(如sd-v1-5-inpainting.ckpt)非常有用。

检测详细信息
https://github.com/dustysys/ddetailer
一个用于Stable Diffusion web UI的目标检测和自动遮罩扩展。

Sonar
https://github.com/Kahsolt/stable-diffusion-webui-sonar
提高生成图像的质量,在已知图像的附近搜索相似(甚至更好!)的图像,专注于单个提示的优化,而不是在多个提示之间切换。


提示旅行
https://github.com/Kahsolt/stable-diffusion-webui-prompt-travel
用于AUTOMATIC1111/stable-diffusion-webui的扩展脚本,用于在潜在空间中在提示之间进行旅行。
示例:(点击展开)

shift-attention
https://github.com/yownas/shift-attention
生成一个在提示中转移注意力的图像序列。这个脚本可以让你给出一个提示中令牌权重的范围,然后生成一个从第一个图像到第二个图像的序列。
https://user-images.githubusercontent.com/13150150/193368939-c0a57440-1955-417c-898a-ccd102e207a5.mp4
种子旅行
https://github.com/yownas/seed_travel
这是一个用于AUTOMATIC1111/stable-diffusion-webui的小脚本,用于创建存在于种子之间的图像。
示例:(点击展开)

嵌入编辑器
https://github.com/CodeExplode/stable-diffusion-webui-embedding-editor
允许您使用滑块手动编辑文本反转嵌入。

潜在镜像
https://github.com/dfaker/SD-latent-mirroring
对潜在图像应用镜像和翻转,可以产生从微妙的平衡构图到完美的反射的效果。

StylePile
https://github.com/some9000/StylePile
一种简单的方法,可以混合和匹配元素到影响结果样式的提示。

推送到🤗 Hugging Face
https://github.com/camenduru/stable-diffusion-webui-huggingface

要安装它,请将存储库克隆到“extensions”目录中,并重新启动Web UI:
git clone https://github.com/camenduru/stable-diffusion-webui-huggingface
pip install huggingface-hub
Tokenizer
https://github.com/AUTOMATIC1111/stable-diffusion-webui-tokenizer
添加一个选项卡,可以预览CLIP模型如何对您的文本进行标记。

novelai-2-local-prompt
https://github.com/animerl/novelai-2-local-prompt
添加一个按钮,用于将NovelAI中使用的提示转换为WebUI中使用的提示。此外,添加一个按钮,允许您调用先前使用过的提示。

Booru标签自动完成
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
显示来自"image booru"板块(如Danbooru)的标签自动完成提示。使用本地标签CSV文件,并包含自定义配置。

Unprompted
https://github.com/ThereforeGames/unprompted
使用这种强大的脚本语言来提升您的提示工作流程!

Unprompted 是 AUTOMATIC1111 的 Stable Diffusion Web UI 的高度模块化扩展,允许您在提示中包含各种短代码。您可以从文件中提取文本,设置自己的变量,通过条件函数处理文本等等 - 就像是强化版的通配符。
虽然预期的用例是 Stable Diffusion,但这个引擎也足够灵活,可以作为通用的文本生成器使用。
training-picker
https://github.com/Maurdekye/training-picker
在 webui 中添加一个选项卡,允许用户自动从视频中提取关键帧,并手动提取这些帧的 512x512 裁剪图像以用于模型训练。

安装
- 安装 AUTOMATIC1111 的 Stable Diffusion Webui
- 根据您的操作系统安装 ffmpeg
- 将此存储库克隆到 webui 内的 extensions 文件夹中
- 将您想要从中提取裁剪帧的视频放入 training-picker/videos 文件夹中
auto-sd-paint-ext
https://github.com/Interpause/auto-sd-paint-ext
AUTOMATIC1111 的 webUI 扩展与 Krita 插件(其他绘画工作室即将推出)

- 优化的工作流程(txt2img、img2img、inpaint、upscale)和用户界面设计。
- 唯一公开脚本API的绘画工作室插件。
请参阅https://github.com/Interpause/auto-sd-paint-ext/issues/41以获取计划中的开发内容。 请参阅CHANGELOG.md以获取完整的更新日志。
数据集标签编辑器
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
这是一个用于编辑Stable Diffusion web UI by AUTOMATIC1111训练数据集中标题的扩展。
它可以很好地处理以逗号分隔样式(例如DeepBooru询问器生成的标签)的文本标题。
可以加载图像文件名中的标题,但编辑后的标题只能以文本文件的形式保存。

美学图像评分器
https://github.com/tsngo/stable-diffusion-webui-aesthetic-image-scorer
扩展程序 https://github.com/AUTOMATIC1111/stable-diffusion-webui 的功能
使用基于 Chad Scorer 的 CLIP+MLP 美学评分预测器 计算生成图像的美学分数
请参阅 讨论
计划将分数保存到 Windows 标签中,并添加其他选项

要研究的艺术家
https://github.com/camenduru/stable-diffusion-webui-artists-to-study
https://artiststostudy.pages.dev/ 适配为 web ui 的扩展程序。
要安装它,请将存储库克隆到 extensions 目录中,并重新启动 web ui:
git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study
您可以通过点击艺术家名称将其添加到剪贴板中(感谢 @gmaciocci 的建议)。

Deforum
https://github.com/deforum-art/deforum-for-automatic1111-webui
Deforum的官方端口,是一个支持关键帧序列、动态数学参数(甚至在提示中)、动态遮罩、深度估计和扭曲的广泛脚本,用于2D和3D动画。

灵感
https://github.com/yfszzx/stable-diffusion-webui-inspiration
随机显示艺术家或艺术流派典型风格的图片,在选择后会显示更多该艺术家或流派的图片。因此,在创作时不必担心选择合适的艺术风格有多困难。

图片浏览器
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
提供一个在Web浏览器中浏览创建的图片的界面,允许按EXIF数据进行排序和过滤。

智能处理
https://github.com/d8ahazard/sd_smartprocess
智能裁剪、字幕和图像增强。

Dreambooth
https://github.com/d8ahazard/sd_dreambooth_extension
在用户界面中使用Dreambooth。请参考项目自述文件以获取调整和配置要求。包括LoRA(低秩适应)
基于ShivamShiaro的存储库。
动态提示
https://github.com/adieyal/sd-dynamic-prompts
为AUTOMATIC1111/stable-diffusion-webui定制的扩展,实现了一个表达式模板语言,用于随机或组合式提示生成,并支持深层通配符目录结构的功能。
更多功能和添加内容请参阅自述文件。

使用这个扩展,提示语句:
A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring} by {2$$artist1|artist2|artist3}
将会生成以下其中一个提示语句:
- 夏天的房子,由artist1、artist2绘制
- 秋天的小屋,由artist3、artist1绘制
- 冬天的别墅,由artist2、artist3绘制
- ...
这对于寻找艺术家和风格的有趣组合特别有用。
你还可以从文件中随机选择一个字符串。假设你在WILDCARD_DIR(见下文)中有一个名为seasons.txt的文件,那么:
__seasons__ is coming
可能会生成以下内容:
- 冬天即将来临
- 春天即将来临
- ...
你也可以使用相同的通配符两次
我喜欢比__seasons__更喜欢__seasons__
- 我喜欢冬天胜过夏天
- 我喜欢春天胜过春天
通配符
https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards
允许您在提示中使用__name__语法,从通配符目录中的名为name.txt的文件中获取一行随机内容。
美学渐变
https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
从一张或几张图片创建一个嵌入,并将其风格应用于生成的图片。

3D模型和姿势加载器
https://github.com/jtydhr88/sd-3dmodel-loader
这是一个自定义扩展,允许您在webui中加载本地的3D模型/动画,或者编辑姿势,然后将截图发送给txt2img或img2img作为ControlNet的参考图像。

画布编辑器
https://github.com/jtydhr88/sd-canvas-editor
这是一个为sd-webui定制的扩展,集成了一个完整功能的画布编辑器,您可以在其中使用图层、文本、图像、元素等。

一键提示
https://github.com/AIrjen/OneButtonPrompt
一键提示是一个用于自动生成提示的工具/脚本,适用于初学者或有困难编写好的提示的高级用户。
它可以从零开始生成一个完整的提示。它是随机的,但是受控的。您只需加载脚本并点击生成,然后让它给您带来惊喜。

模型下载器
https://github.com/Iyashinouta/sd-model-downloader
这是一个SD-Webui的扩展,用于从CivitAI和HuggingFace下载模型,推荐给云用户(如Google Colab等)。

SD Telegram
https://github.com/amputator84/sd_telegram
SD Telegram是一个基于aiogram的Telegram机器人,用于在本地生成图片(当前为127.0.0.1:7860 nowebui)。
如果您想通过Telegram机器人来管理它,请通过扩展进行安装。 更多的说明在GitHub上。 该机器人使用sdwebuiapi,并且与本地地址配合工作。
能够生成预览图、全尺寸图片,还可以发送文档和群组。
能够“组合”提示,从lexica获取,其中有一个用于所有模型的流生成脚本。
QR Code Generator
https://github.com/missionfloyd/webui-qrcode-generator
即时生成用于ControlNet的QR码。
